Time Parameters
Description
This section is from the book "Computer Security Threat Monitoring And Surveillance", by James P. Anderson.
Time Parameters
There are basically 2 time parameters of interest that characterize how a system is used for a particular job. The first of these is the time of day (and in a larger sense the day of the week) that a particular job or session is operated. For many jobs this time of use is fi&ed within a fairly narrow range.
The second time parameter is the the duration of length of time the job takes. While the fact that most modern systems are multi programmed and the elapsed real time for - job will vary accordingly, it is still a measure that one would ordinarily expect to have relatively little variability.
The time of day of the job initiation is one of the few -use parameters with multiple values. Depending on the kind of user being characterized, the time of initiation of a particular task or job will vary, perhaps substantially. This is especially true in the case of interactive working where the choice of when to do a particular kin^ of task is totally up to the user under observation.
While system usage patterns can exhibit wide fluctuations from one user to another, it is expected that individual users establish patterns to their use of a system. It is these patterns that will be disturbed by masquerades.
Further, it should be evident that the ability to discriminate a particular indicator is a function of how wdely the individuals own pattern of use fluctuates from day-to-day, and week-to-week.
This is well illustrated by the example given below where the ability to detect use of a resource outside of 'normal1 time cannot be achieved if 'normal' time can be any hour of the day, any day of the week.
Detection of outside of normal times of use is relatively straightforward. Individual jobs (sessions, job steps, etc.) are sorted on time of initiation and compared with previously recorded data for the specific user.
The basic question to be faced is the granularity of the analysis needed to detect 'out of time' use of a resource. For users exhibiting little variability in their use of a system, a gross measure, such as number of jobs (sessions, etc.), per quarter of the day (0000 - 0559, 0600 - 1159, ... etc.) will be sufficient to discover second or third shift use of a system under the name of the subject under observation.
For another class of user, with considerable variability in time of use, it may be necessary to record usage by the hour. Obviously, if the 'normal' use is every hour of the day, the 'outside of normal time' condition is not detectable. One would have to examine such users further to determine whether the normal use extends seven days a week, on holidays, through vacations, etc. Conceivably, 'normal' usage could extend through all of these periods. Then, the 'out of normal time1 condition would not be a useful discriminant for that user.
Figure 2 shows the number of logons per hour for two different days (approximately 20 days apart) for a number of different users. Users I, II, and IV exhibit consistent patterns of logon, while users III and V exhibit more variability (in these two samples).

Figure 3. Number of Logons Hr.
If (for purposes of illustration) we assume that the fA' data is the average (or cumulative) experience with the user in question, the variability in time of use could be scored by summing the squares of absolute values of the difference, i.e..
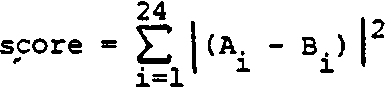
While not a particularly elegant measure, it does show for the several users represented, those whose logon pattern exhibit greatest variability, which might be the result of masquerade. Depending on other measures, those users might then become subjects of additional investigations.
The time of use abnormality scores for the five samples are:
User | Score |
I | 0 |
II | 8 |
III | 107 |
IV | 11 |
V | 41 |
Depending on where the cutoff point is set for reporting, one would expect to see * III* and 'V1 reported as being out of range.
In addition to the elapsed real time for a particular problem, we can measure the actual computer time used on a particular problem. This measure should not vary substantially, but a heavy system load which causes programs to be swapped in and out frequently can increase the elapsed running time for the problem. The increase should not be significant unless there is some other reason.
Dataset And Program Usage
The parameters that can be measured in this area varies significantly from one system to another. In some cases it is possible to identify the number of records read and written to a particular dataset or file while in another case on another system, the only data reference information that would be available would be a total number of pages transferred between a file system to a processor, with no indication being given whether those pages were read or written. These differences are a result of the fact that the audit data is taken for accounting purposes rather than security purposes, and as a consequence the kind of information that's collected is driven by accounting interests rather than what one would prefer for security purposes.
With regard to program usage the principal concern as far as security audit goes is whether or not a program was referred to for execution purposes or whether it is being read and written as data. This is significant for a security viewpoint because of the fact of reading and writing of programs as data is almost certainly a clue of penetration activity as opposed to normal system use. It must be understood that the reading and writing programs as data does not mean the results of compilation. Thus the principle data parameter for programs or data files is the number of records read or written.
Monitoring Files And Devices
The preceding discussion focused on the monitoring of a particular user identifier through the range of actions that the user identifier is allowed to do include submitting jobs, use of system and so forth. It is indeed the monitoring of system users that is the focus of the preceding kihds of surveillance and monitoring techniques. When one shifts the attention to monitoring a particular file or correspondingly a device, the kind of information collected, how it is collected and how it is used differs.
Group Statistics
While one could attempt to detect abnormal values of parameters against all of the job records for a single user, it is believed that better measures and better security can be obtained by grouping the job records into sets having the property that each job or session refers to the same set of files? that is, an identical set of files.
The presumption is that the session or job referring to the same file sets can be considered to belong to the same population and will exhibit similar statistical properties from run to run. An arbitrary deviation of the norm for the user is a criterion for reporting a particular use and generating an "abnormal volume of data" or an "abnormal (measure of one of the parameters discussed above) exception". With no other data available, if the observed statistic for a parameter is more than plus or minus 2.58 standard deviations from the mean, it is out in the five percent range and probably is worthy of examination.
The abnormal patterns of reference are determined simply by discovery of file references that have not been previously encountered. If the files referenced in a particular job are not identical to a set previously seen, this should be reported as a new event. In the section on the organization of a surveillance system, some of these comments are, illustrated with the results of a model system.
Continue to: